



{kind=link}
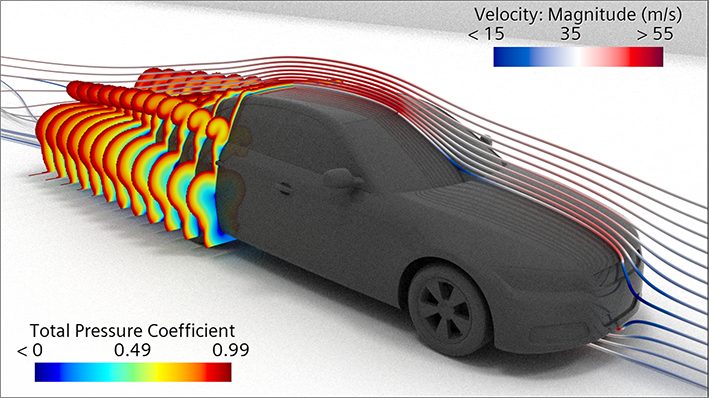
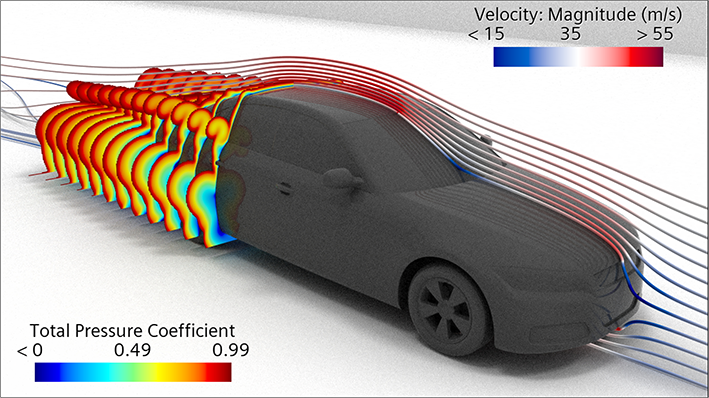
Som en av marknadsledarna inom fordonsutveckling sätter BMW nya riktmärket inom fordons-aerodynamik och strävar efter extrem precision genom att använda skalupplösande, transienta simuleringar, som inkluderar stela karossrörelser för hjulen. Genom att simulera fälgarnas verkliga rotation fångas de komplexa effekterna av däckens kölvatten inom ramen för fordonets totala prestanda.
”Dessa simuleringar är utformade för att noggrant fånga de komplexa luftflödes-interaktionerna mellan roterande däck och fordonets övergripande aerodynamik”, förklarade NVIDIAs Ian Pegler under GTC-presentationen 2025.

Ett nytt riktmärke för fordons-aerodynamik
Siemens simuleringslandskap förändrades dramatiskt under 2022 när denna globalt ledande PLM-aktör presenterade nativ server-GPU-acceleration för Simcenter STAR-CCM+, vilket skapade ett nytt kapitel för traditionella CPU-bundna arbetsflöden. Genom ett nära samarbete med NVIDIA kring CUDA, möjliggjorde Siemens att kritiska lösare – inklusive kopplade och segregerade metoder för komplex fluiddynamik – kunde köras direkt på GPUer. NVIDIA CUDA (Compute Unified Device Architecture) är en plattform för parallellberäkning och en programmeringsmodell som gör det möjligt att använda NVIDIAs grafikprocessorer (GPUer) för generella, tunga beräkningar, inte bara grafik.
{kind=link}
Prestandasprånget blev transformerande: en enda servernod utrustad med åtta NVIDIA H100/H200 GPUer kunde nu leverera över 30 gånger hastigheten jämfört med en standard CPU-baserad installation.

Enligt NVIDIA innebär detta att en nod med 8 GPUer kan ersätta mer än 50 noder med endast CPU och samtidigt ge motsvarande, eller till och med snabbare handläggningstider. Denna förändring gör det möjligt för ingenjörer att hantera massiva, komplexa simuleringar på en bråkdel av tiden, vilket gör högpresterande simulering mer kostnadseffektiv och tillgänglig.
Medan modellering av fälgarnas exakta rörelse ger ett avgörande lager av återgivning, kräver det traditionellt betydande beräkningsresurser.
”Att flytta denna arbetsbelastning till GPUn gör det möjligt för oss att bibehålla den höga noggrannhetsnivån samtidigt som vi drastiskt accelererar simuleringshastigheten”, konstaterade Ian Pegler. ”Slutsats: BMWs resultat visar tydligt att GPU-drivna arbetsflöden är nästa generations lösning för Computational Fluid Dynamics.”
”Detta är dock inte uteslutande ett BMW-fenomen”, tillade han. ”Vi ser en utbredd branschförskjutning mot GPUer. Även om samtalet kring GPU-acceleration för CFD har cirkulerat i åratal, skulle jag vilja hävda att det bara är under de senaste två till tre åren som vi verkligen har sett en utbredd användning i praktiska, verkliga tillämpningar.”

Vilka är orsakerna till denna utveckling?
”En är att jag tror att många av koderna, som Star Citizen Plus, nu har flyttat Solve helt till GPUn. Tidigare fanns det fortfarande delar kvar på CPUn, medan majoriteten av Solve nu körs på GPUn, vilket är där man får dessa mycket höga hastighetsökningar, vilket är prisvärdt och rimligt.”
Koder eller verktyg som ofta hänvisas till i samband med ”Star Citizen Plus” eller liknande förbättringspaket fungerar i allmänhet som prestandajusterings-mekanismer, utformade för att flytta belastningen mellan CPU och GPU. I ett CPU/GPU-sammanhang syftar dessa verktyg till att lösa Star Citizens ökända CPU-bundna flaskhalsar genom att avlasta arbete till GPUn eller hantera systemresurser bättre.

”En annan viktig anledning är att GPU-tekniken uppenbarligen har utvecklats mycket, särskilt från och med A100, när vi hade 80 GB GPU-minne som gjorde det möjligt att köra den här typen av industriella problem på en GPU mycket mer effektivt. Ökningen av minne och minnesbandbredd, särskilt med H200 och framåt, 141 GB minne, 2,8 terabyte minnesbandbredd har verkligen gjort GPU, och uppenbarligen B200 efter det, till ett mycket bra alternativ, eftersom storleken på modellen du kan köra med så mycket minne är så mycket större nuförtiden.”
”Ofta är den här typen av CFD-simulering bundna till minnesbandbredds-nivån, så mer minnesbandbredd korrelerar direkt med hastigheten. Vilket innebär att vi vill ha mer minne och mer minnesbandbredd. Med mer minnesbandbredd går saker snabbare, och vi kan köra större modeller på samma GPU.”
Kraften i Siemens och NVIDIAs simuleringslösningar
Det är tydligt att kombinationen av NVIDIAs GPU-kraft och Siemens Simcenters simuleringslösningar har skapat en intressant marknadsposition.
NVIDIAS GPU-teknik har hjälpt den tyska PLM-världsledaren med bland annat:
• Betydande hastighetsökningar inom simulering (CFD): Genom att använda NVIDIA CUDA-plattformen körs Siemens Simcenter STAR-CCM+ på GPU:er för att leverera prestanda där en enda GPU-nod kan ersätta över 50 CPU-enbart noder. Till exempel, i turbinblads LES (Large Eddy Simulation)-arbetsflöden minskade GPU-acceleration simuleringstiderna med över 77 % jämfört med CPU-kluster.
• Förbättrade designiterationer (Shift Left): Den höga hastigheten gör det möjligt för ingenjörer att ”shifta left” – d v s utföra högkvalitativa, komplexa simuleringar tidigt i designfasen, vilket gör att de kan testa hundratals aerodynamiska konfigurationer.
• Sänkta kostnader och energiförbrukning: GPU-baserade simuleringar erbjuder en lägre total ägandekostnad (TCO) och minskar energiförbrukningen avsevärt – ibland till 35 % av den effekt som behövs för motsvarande CPU-körningar. Siemens och NVIDIA demonstrerade att GPU-användning skulle kunna minska den nödvändiga hårdvaruinvesteringen med upp till 40 %.• Högkvalitativ modellering av komplexa flöden: GPU-kraft möjliggör simulering av komplex aerodynamik, såsom roterande fälgar eller flöden under huven i bilar, med högre återgivning (t.ex. LES istället för RANS).
• Realtidsvisualisering och digitala tvillingar: Partnerskapet integrerar NVIDIA Omniverse med Siemens Simcenter, vilket möjliggör fotorealistisk visualisering av aerodynamisk data i realtid, vilket gör det enklare för ingenjörsteam att analysera designflödeskvaliteter, såsom luftmotstånd och lyftkraft.
• Generativ simulering och AI-integration: Framtidsfokuserade insatser inkluderar träning av AI-modeller på NVIDIA-infrastruktur för att föreslå optimala aerodynamiska former innan en enda fullständig CFD-simulering körs, vilket påskyndar utvecklingen från år till månader.
Under 2026 utökades partnerskapet mellan Siemens och NVIDIA till att använda de senares Blackwell-GPUer, med målet att uppnå ännu snabbare prestanda och djupare AI-integration i Siemens Xcelerator-plattformen.
Varför GPUer är viktiga för AI
GPUer är således av stor betydelse i AI-lösningar eftersom deras arkitektur är utformad för parallell bearbetning, vilket gör att de kan utföra tusentals små, samtidiga beräkningar. Detta gör dem idealiska för massiva matrismultiplikationer och linjär algebra är grundläggande för djupinlärning och träning av neurala nätverk, vilket skulle ta mycket längre tid på traditionella processorer.
• Massiv parallellitet: Till skillnad från processorer, som är utformade för sekventiell bearbetning (hantering av uppgifter en efter en), innehåller GPU:er tusentals mindre, specialiserade kärnor som arbetar tillsammans för att skära igenom komplexa dataintensiva uppgifter.
• Accelererad träningstid: Att träna komplexa AI-modeller kräver enorm beräkningskraft. GPU:er kan minska träningstiderna från dagar eller veckor till timmar, vilket möjliggör snabbare experiment, modellförfining och accelererad time-to-market.
• Realtidsinferens: När en modell är tränad måste den göra förutsägelser om ny data (inferens). GPUer ger den låga latens och höga genomströmningskapacitet som behövs för realtidsapplikationer som självkörande bilar, chatbotar och ansiktsigenkänning.
• Hantering av stora datamängder: Modern AI, särskilt generativ AI och stora språkmodeller (LLM) som GPT-4, involverar biljoner parametrar. Grafikkort tillhandahåller den höga minnesbandbredd (t.ex. HBM3e) och minneskapacitet som behövs för att bearbeta dessa massiva datamängder effektivt.
• Specialiserad AI-hårdvara (Tensor Cores): Moderna grafikkort (t.ex. NVIDIA H100/H200) inkluderar specialiserad hårdvara som kallas Tensorkärnor, vilka är specialbyggda för att accelerera den matrismatematik som är avgörande för AI, vilket ökar prestandan med flera storleksordningar jämfört med äldre eller allmänt ändamålsenlig hårdvara.
{kind=link}
• Brett programvaruekosystem: Programvaruekosystem som NVIDIAs CUDA- och cuDNN-bibliotek gör det möjligt för utvecklare att enkelt utnyttja GPU:ernas råa kraft och skapa en standardplattform för AI-utveckling.
Medan processorer (Central Processing Units) är ”allmänna” hanterare, utmärker de sig på sekventiell logik. AI handlar mindre om komplex logik och mer om att göra samma enkla matematik miljarder gånger parallellt. En grafikkort beter sig mer som en ”multitasking-maestro”, vilket möjliggör 10x–100x snabbare träning än system med enbart CPU.

GPU-tekniken är avgörande
De främsta orsakerna bakom denna GPU-revolution är flera:
• En viktig är att GPU:er har tusentals mindre specialiserade kärnor, till skillnad från CPU-processorer, som har ett fåtal kraftfulla kärnor för sekventiella uppgifter. Dessa mindre GPU-kärnor utmärker sig vid SIMD-körning (Single Instruction, Multiple Data), vilket gör att de kan beräkna partikelfysik, nätelement eller pixelförändringar samtidigt.
• Dessutom minskar GPU-acceleration – med hastighetsökningar på 10x till 100x+ – simuleringstiden avsevärt. Till exempel, inom fluiddynamik (CFD), kan en enda GPU prestera på nivån av över 400 CPU-kärnor. I specifika scenarier har GPU-accelererade simuleringar visat över 700 gånger högre prestanda jämfört med 4-kärniga CPU-simuleringar.
• En viktig fördel med GPUer är att de möjliggör realtids- och komplexa simuleringar: GPU:ernas hastighet möjliggör interaktiv realtidssimulering, vilket ändrar arbetsflödet från en ”simulera över natten”-metod till en ”designa och analysera i farten”. Det möjliggör också användning av mer realistiska, icke-förenklade modeller.
• Enhetlig simulering och AI-pipelines: Moderna GPU-plattformar (som NVIDIA CUDA-drivna system) gör det möjligt för forskare att köra fysiskt baserade simuleringar och AI-modellträning (maskininlärning) inom en enhetlig miljö, vilket minimerar dataöverföringskostnaderna.
• En annan viktig fördel är hög minnesbandbredd (VRAM). GPU:er använder högbandbreddminne (VRAM) som möjliggör snabb hämtning av stora mängder data och kringgår de flaskhalsar som är typiska för CPU:ns huvudminne. Detta höghastighetsminne är avgörande för att hantera komplexa modeller med hög upplösning.
• I detta sammanhang är det vanligt att tala om värdet av att demokratisera högpresterande datoranvändning (HPC). GPU:er är mer kostnadseffektiva och energieffektiva än traditionella CPU-kluster. En enda GPU-server kan leverera jämförbar prestanda med ett massivt CPU-kluster till en bråkdel av hårdvaruinköpet och energikostnaden.
Viktiga transformerade tillämpningsområden
Beräkningsvätskedynamik (CFD): Modellering av komplexa flödesmönster, aerodynamik och hydrodynamik, värmeöverföring och elektromagnetism.
Autonoma fordon (AV): Högkvalitativ sensorsimulering och realtidsbeslutsfattande för självkörande bilar.
Molekylär dynamik: Simulering av tusentals atomer för läkemedelsutveckling.
Strukturmekanik/FEA: Komplex strukturanalys med förfinade nät.
Slutligen, visste du att STAR-CCM är en förkortning för ”Simulation of Turbulent flow in Arbitrary Regions – Computational Continuum Mechanics” (På svenska: Simulering av turbulent flöde i godtyckliga regioner”)

